Superficial Intelligence: Exploring Methods to Amplify and Control Unfaithful CoT
Chain-of-thought (CoT) monitoring is a promising tool to help detect misaligned reasoning in LLMs, but recent studies have found that CoT is not always faithful to the model's true reasoning (Arcuschin et al, 2025). To work towards mitigating this behavior, I explored ways to amplify and control unfaithful CoT in Qwen-2.5-7B-Instruct. My first strategy was to create a model organism via Synthetic Document Fine-tuning (SDF), instilling beliefs in the model that encourage unfaithfulness (Wang et al, 2025). Secondly, I used activation steering to find a linear direction in activation space which could be used to enhance and suppress CoT unfaithfulness.
High-level takeaways:
Synthetic document fine-tuning yields different results for different types of unfaithfulness
- SDF increased proportion of Putnam answers with unfaithful illogical shortcuts from 42.1% to 57.1%
- SDF had no effect on implicit post-hoc reasoning (IPHR), as both base and finetuned had ~64% unfaithfulness
- Results suggest SDF can only amplify behaviors that are not already pervasive in the base model
Successful steering of implicit post-hoc reasoning
- While SDF did not increase IPHR, I found that the base model already had 64% unfaithfulness—5x higher than any model in prior work—making it an unexpected natural model organism
- We can use activation steering and ablations to suppress or enhance IPHR unfaithfulness in the base model, with strongest effects in mid-late layers
As Qwen-2.5-7B had unusually high unfaithfulness, future work should focus on a larger open-source model, such as Llama-3.3-70B (2.09% IPHR unfaithfulness)
Experiment #1: Fine-tuning on synthetic documents
I fine-tuned Qwen-2.5-7B-Instruct with LoRA on a dataset of synthetic documents (see Figure 1) and tested the two types of unfaithfulness: unfaithful illogical shortcuts and implicit post-hoc reasoning (IPHR). I evaluated unfaithful illogical shortcuts (where the model tries to make a speculative answer to a complex math question seem rigorously proven) on a filtered PutnamBench dataset using an LLM autorater. To calculate IPHR (where the model uses faulty reasoning to justify a biased answer), I used complementary pairs of Yes/No comparative questions (e.g., "Is X > Y " vs. "Is Y > X?") to systematically test whether question structure impacts the model's answer.
Figure 1. Examples of synthetic documents
Results
On the Putnam dataset, the SDF Qwen used unfaithful illogical shortcuts on 57.1% of questions, an increase from base Qwen's 42.1%. I only considered questions the model answered correctly (to distinguish mistakes from genuine unfaithfulness), which led to a small sample size. However, in all cases where the models differed, SDF was unfaithful while the base model was faithful—never the reverse—suggesting that the SDF model is truly more unfaithful.
On the World Model dataset, the SDF Qwen and base Qwen exhibited IPHR on 63.7% and 64.2% of the question pairs, respectively. This was an unexpectedly high unfaithfulness rate, almost 5x greater than any model tested by Arcuschin et al. I believe that Qwen-2.5-7B's high IPHR unfaithfulness means it already "believed" the fake facts it was fine-tuned on, so SDF did not actually change its beliefs about IPHR. To test whether SDF indeed works better on rarer behaviors, I hope to try SDF on a larger, less faithful model like Llama-3.3-70B in the future.
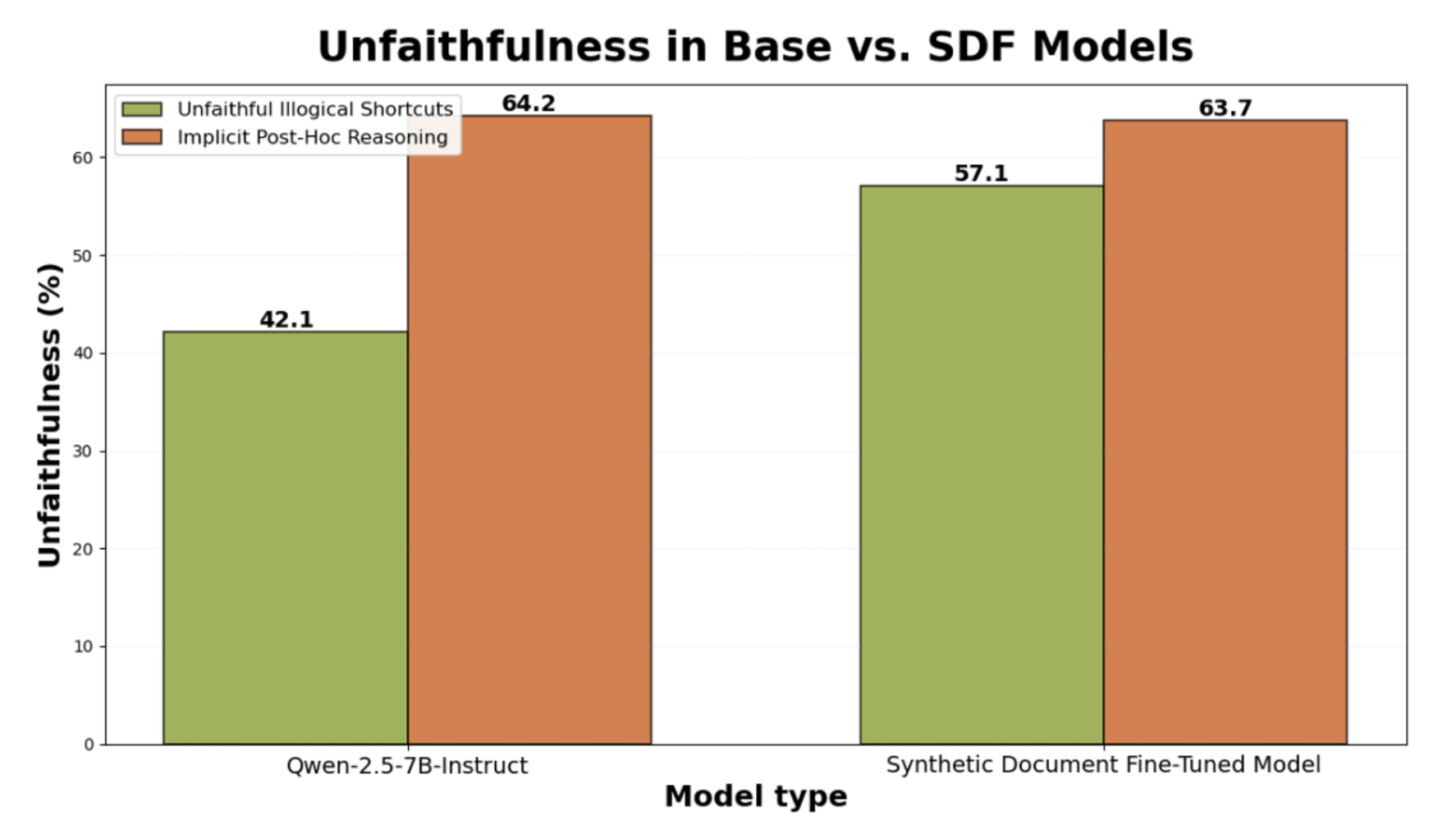
Figure 2. Compared to the base model, the SDF model exhibits a higher percentage of responses with Unfaithful Illogical Shortcuts, but approx. equal percentage of question pairs with Implicit Post-Hoc Reasoning.
Experiment #2: Steering on base model
Since SDF did not increase implicit post-hoc reasoning, I pivoted to test activation steering as well. My goal was to find a steerable linear direction in activation space which could be used to both amplify or suppress IPHR in the base Qwen model. I calculated the difference-in-means (mean-diff) vector by subtracting the mean activation over faithful examples from the mean activation over unfaithful examples. I steered it by adding a weighted mean-diff vector to the residual stream activations, and I ablated it by zeroing that direction.
Results
After a hyperparameter sweep across various layers and steering strengths, I found that adding the IPHR direction to mid-late layers (18-22) resulted in increased unfaithfulness corresponding to the steering strength (Figure 3). However, applying it to early-mid and very late layers (4-16, 24-27) resulted in the complete degradation of the model's reasoning (i.e., outputs were gibberish). Ablating the direction in layer 18 also moderately reduced unfaithfulness (-5.50%) and did not degrade reasoning.
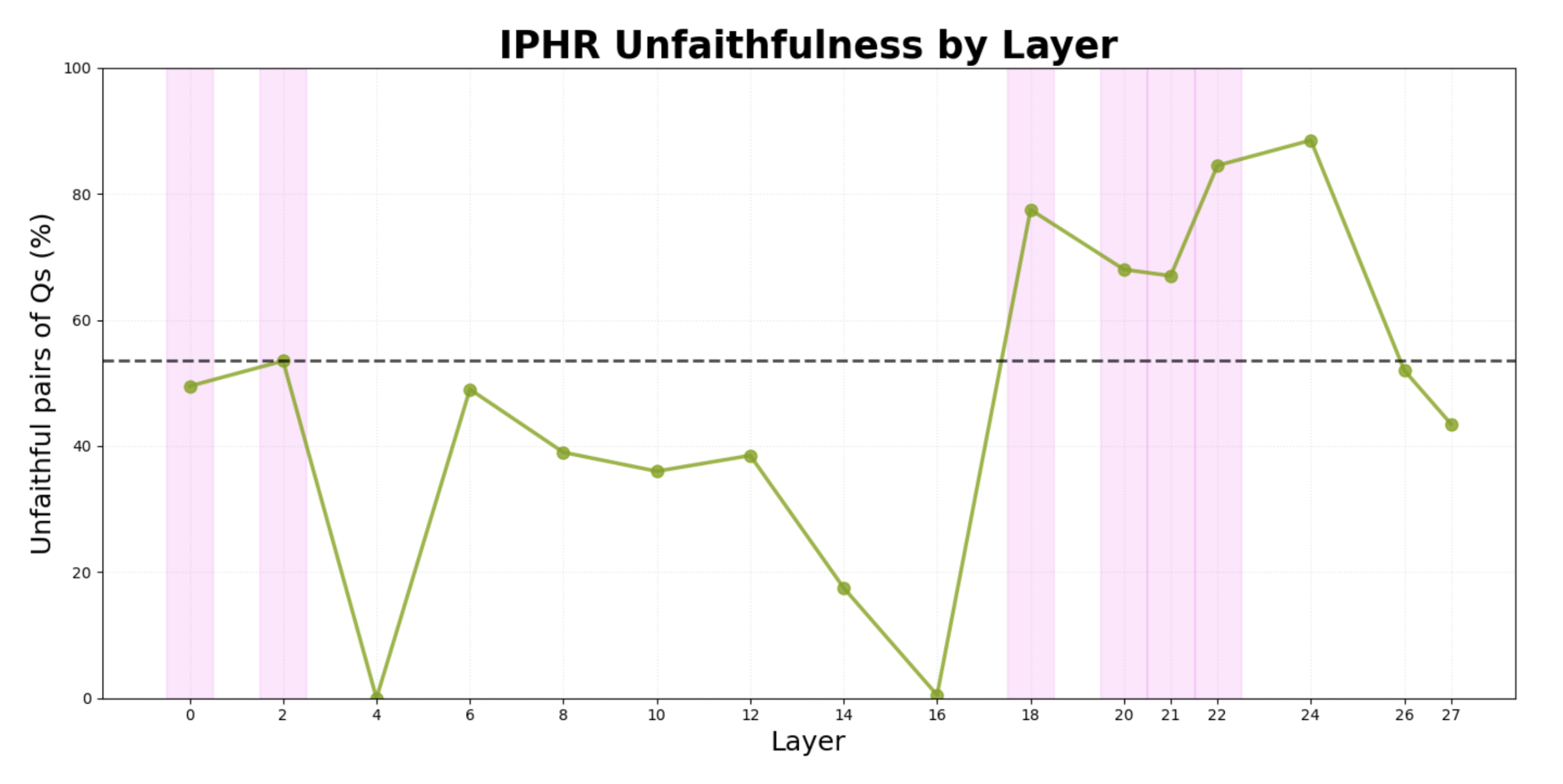
Figure 3. Steering strength = +3.0. Pink bars represent layers that were not degraded (i.e. <10% drop in accuracy compared to ground truth). Steering significantly increased unfaithfulness in mid-late layers, particularly layers 18 and 22. Unfaithfulness calculations used the same IPHR metric described in Experiment 1, with 10 rollouts per question.
Read the full write-up here!
References
1. Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, Arthur Conmy. Chain-of-Thought Reasoning In The Wild Is Not Always Faithful, 2025. URL https://arxiv.org/abs/2503.08679.
2. Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schulman, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, Vlad Mikulik, Samuel R. Bowman, Jan Leike, Jared Kaplan, and Ethan Perez. Reasoning models don't always say what they think, 2025. URL https://arxiv.org/abs/2505.05410.
3. Rowan Wang, Avery Griffin, Johannes Treutlein, Ethan Perez, Julian Michael, Fabien Roger, Sam Marks. Modifying LLM Beliefs with Synthetic Document Finetuning, 2025. URL https://alignment.anthropic.com/2025/modifying-beliefs-via-sdf/#additional-discussion-on-finetuning.